AWS (5) - Load Balancing & Auto Scaling Group
·7 min read
Scalability & High Availability
- 애플리케이션이 스케일링 한다 = 적응하여 더 큰 부하를 처리할 수 있다.
- 확장성에는 두 종류가 있다
- 수직 확장성 Vertical Scalability
- 수평 확장성 Horizontal Scalability (=탄력성 elasticity)
- 확장성은 고가용성과 연관되어 있지만 둘은 다른 것이다.
Vertical Scalability
- 인스턴스의 크기를 증가시키는 것.
- t2.micro → t2.large
- 데이터베이스 같은 분산되지 않은 시스템에서 주로 사용함
- 수직 확장성에는 매우 높지만 한계가 있다. (하드웨어 한계)
Horizontal Scalability
- 애플리케이션을 위한 인스턴스, 시스템의 숫자를 늘리는 것
- 분산 시스템에 적용된다. 웹 애플리케이션이나 현대적인 애플리케이션은 수평 확장성을 염두에 두고 개발해야 함.
High Availability
- 수평 확장성과 잘 어울리는 개념.
- 애플리케이션, 시스템을 최소 2개 이상의 가용영역에서 실행하는 것.
- 데이터 센터의 손실과 같은 재앙에서 살아남는 것이 목적.
Scalability vs Elasticity ( vs Agility)
- 확장성은 하드웨어를 더 강하게 하거나 (스케일 업) 노드를 추가 (스케일 아웃)하여 시스템이 더 큰 부하를 수용할 수 있게 한다.
- 탄력성이란 오토 스케일링을 의미한다. 수신하는 로드에 따라 시스템이 자동으로 확장하는 것. 사용량에 따라 비용을 지불하며 수신되는 수요를 서버 숫자와 일치시키고 비용을 최적화한다.
- 민첩성은 확장성, 탄력성과 전혀 관계가 없고 혼동을 주기 위한 단어.
로드 밸런싱
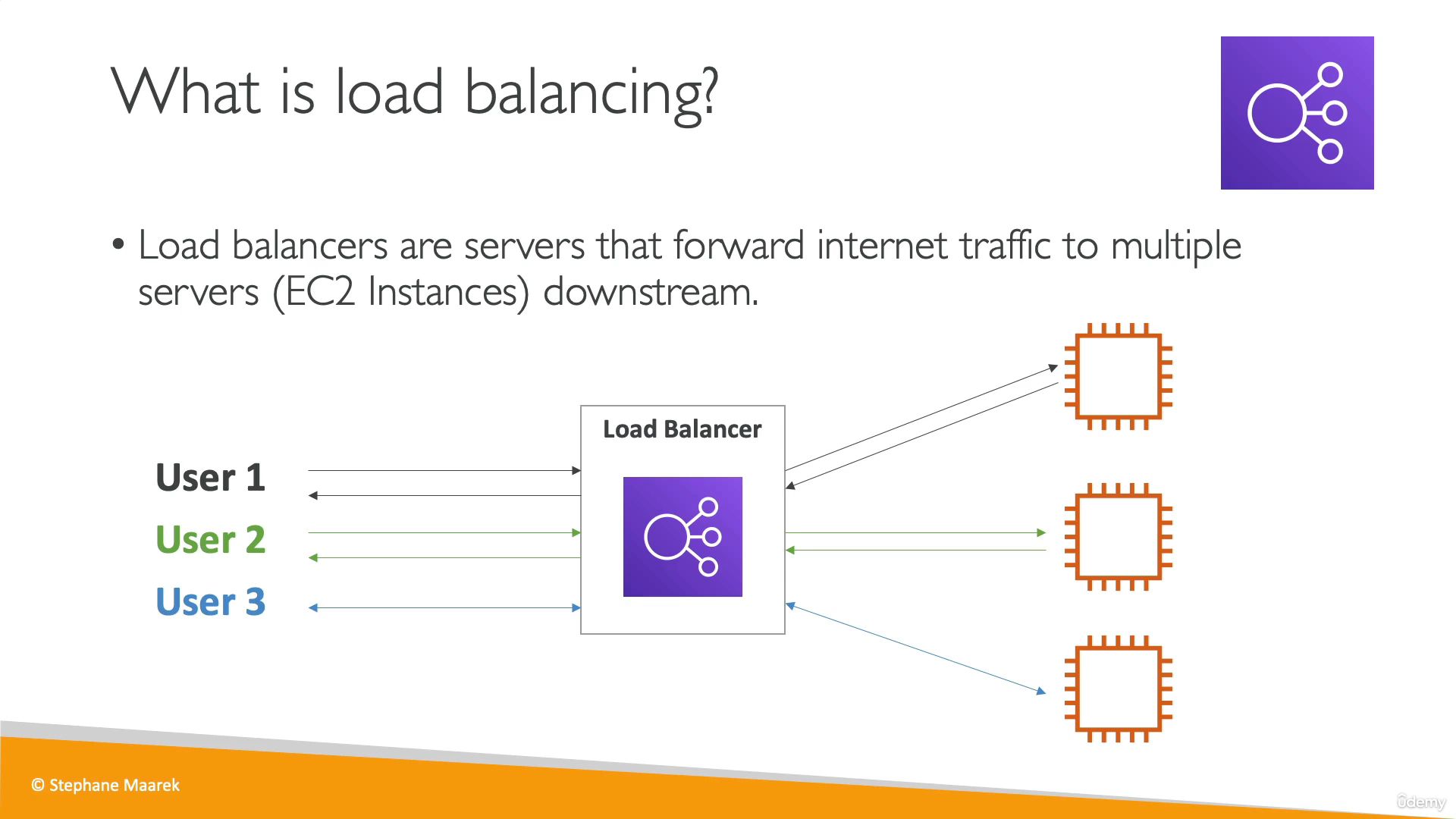
- 인터넷 트래픽을 다운스트림에 있는 여러 서버로 전달.
- 애플리케이션에 대한 단일 액세스 지점 (DNS)를 노출할 수 있다.
- 다운스트림 인스턴스의 실패를 원활하게 처리할 수 있다. 정기적으로 인스턴스 상태를 체크해서, 하나가 실패하면 로드밸런서는 트래픽을 해당 인스턴스가 아닌 곳으로 보낸다.
- SSL 종료를 제공할 수 있다. (HTTPS)
- 여러 가용 영역에 걸쳐서 로드밸런서를 이용할 수 있다. (높은 가용성)
- ELB (Elastic Load Balancer)는 관리 로드 밸런서이다. 서버를 프로비저닝 할 필요없이 AWS가 해준다.
- AWS가 잘 작동될 것을 보장한다. 업그레이드, 유지보수, 고가용성을 관리해준다.
- 우리는 로드밸런서를 사용하도록 몇가지 구성만 하면 됨.
- EC2에서 자체적으로 로드밸런서를 구성하면 훨씬 비용이 저렴하다. 그러나 유지보수 관리가 쉽지 않음. AWS 것을 쓰면 편함.
로드 밸런서의 종류
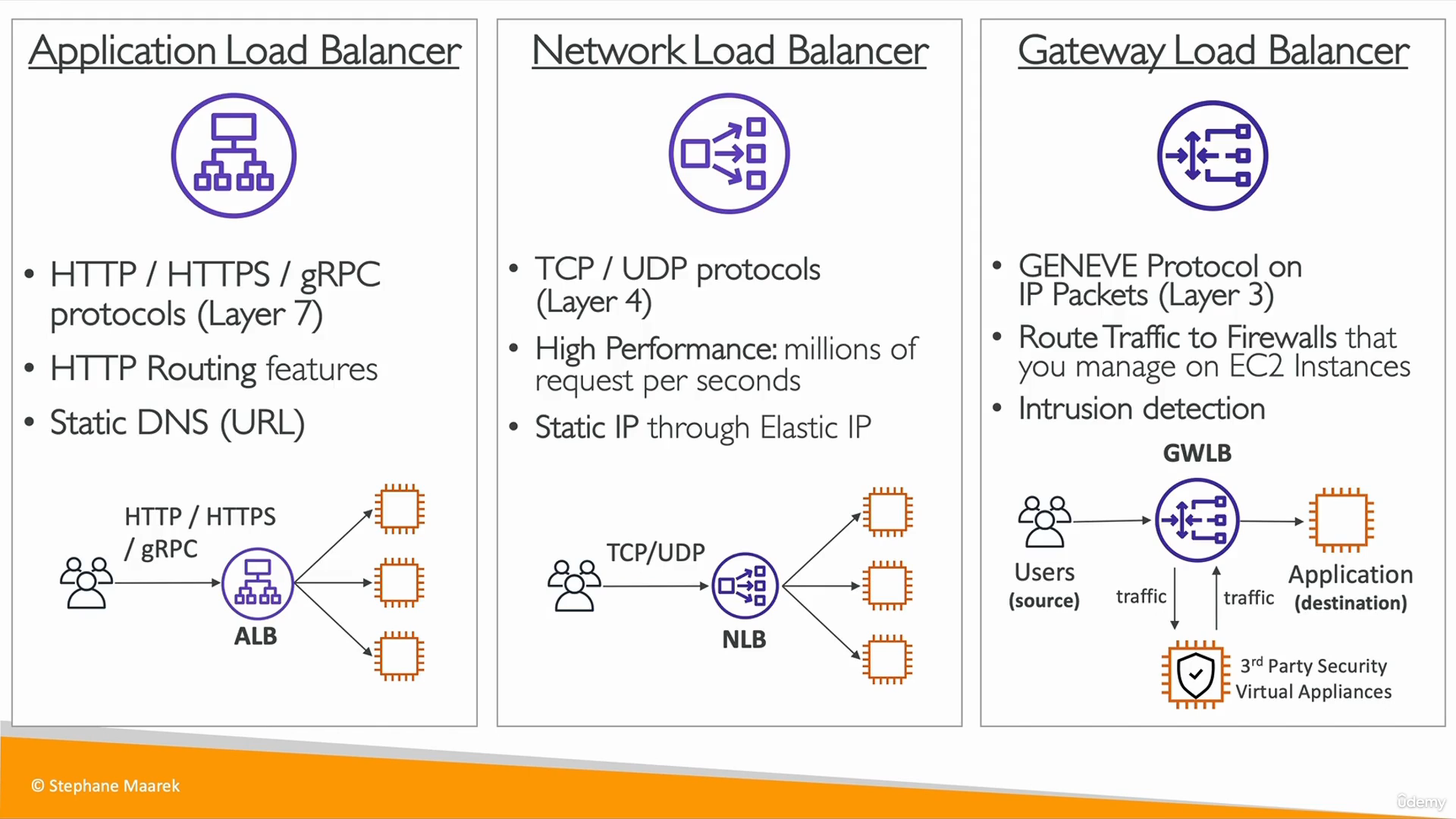
- 애플리케이션 로드 밸런서 (HTTP / HTTPS only) - Layer 7
- 네트워크 로드 밸런서 (ultra-high performance, allows for TCP) - Layer 4
- 게이트웨이 로드 밸런서 - Layer 3
클래식 로드 밸런서 (slowly retiring) - Layer 4 & 7 - 2023년에 사라짐.
Application Load Balancer
- HTTP / HTTPS / gRPC (Layer 7)
- HTTP Routing features
- Static DNS (URL)
Network Load Balancer
- TCP / UDP (Layer 4)
- High Performance : 초당 수백만의 요청을 처리
- Static IP through Elastic IP
Gateway Load Balancer
- GENEVE Protocol on IP Packets (Layer 3)
- EC2 인스턴스에서 관리하는 방화벽으로 트래픽을 라우팅한다.
- Intrucsion detection (침입 감지, 심층 패킷 검사)
Auto Scaling Group 이란?
- 현실에서 웹사이트 로드는 시간대에 따라 다르다.
- 클라우드에서는 매우 빠르게 서버를 만들고 없앨 수 있다.
- Auto Scaling Group의 목적은
- 늘어난 로드에 맞춰 스케일 아웃 (EC2 인스턴스 추가)
- 줄어든 로드에 맞춰 스케일 인 (EC2 인스턴스 제거)
- 어느 시점이든 실행하는 머신 숫자를 최소, 최대로 보장할 수 있다.
- 새로운 인스턴스들이 로드 밸런서에 자동으로 등록된다.
- 비정상 인스턴스를 감지한 후 대체한다.
- 항상 최적의 용량에서 실행하기 때문에 비용 절감의 이점이 있다.
스케일링 전략
- 수동 스케일링 - 오토 스케일링 그룹 크기를 수동으로 업데이트
- 동적 스케일링 : 수요에 따라 자동으로 대응
- 단순 / 단계 스케일링
- CloudWatch 경보가 트리거 됐을 때 (CPU > 70%), 2 유닛 추가.
- 다른 경보가 트리거 됐을 때 (CPU < 30%), 1 유닛 제거.
- 대상 추적 스케일링
- 모든 인스턴스의 CPU 사용률을 40%로 유지.
- 예약 스케일링
- 사용자 패턴을 기반으로 확장을 예측.
- 금요일 오후 5시에 이벤트가 있다면 최소 용량을 10까지 늘린다.
- 예측 스케일링
- 머신러닝을 사용하여 트래픽을 예측. 과거의 패턴을 기반으로 예측함.
- 예측 기간이 도달하기 전에 자동으로 인스턴스를 프로비저닝.
- 단순 / 단계 스케일링